Regulated organizations didn't fall in love with generative AI because it writes fluent paragraphs. They fell in love with the idea of compressing the time between "question asked" and "decision defended."
But regulated environments have an allergy to ungrounded prose. A model that "sounds right" is not a system you can supervise, audit, or explain under pressure.
That's why the future doesn't look like a free-form chatbot bolted onto a document drive. It looks like RAG copilots: systems that treat enterprise knowledge as the primary source of truth, and treat the LLM as a reasoning-and-language layer constrained by retrieval, policy, and evidence.
At Ishtar AI, we think the winners in this space will build copilots that are:
- Evidence-first (every claim is attributable),
- Policy-aware (access, jurisdiction, and confidentiality are enforced before generation),
- Auditable by design (traceability is a product feature, not an afterthought),
- Measurable (quality is evaluated like a risk system, not a demo).
Below is a technical view of where RAG copilots are going—especially for compliance and research workflows—and what best practices separate pilots from production systems.
Why regulated teams need RAG, not "just an LLM"
A base LLM is fundamentally a probabilistic text generator trained on broad patterns. In regulated environments, that creates immediate friction:
- Supervision and recordkeeping: You don't just need an answer—you need what it was based on, who was allowed to see it, and what version of the truth existed at that time.
- Sensitive-data boundaries: "Helpful" becomes "harmful" if retrieval crosses confidentiality tiers, privileged sources, or internal segregation rules.
- Defensibility: A decision that can't cite underlying policy language, procedures, communications, or evidence is fragile.
- Operational risk: Hallucinations aren't just incorrect—they are uncontrolled statements that can propagate into downstream documents, customer communications, and approvals.
Retrieval-Augmented Generation (RAG) changes the center of gravity. Instead of asking a model to invent, you ask it to retrieve from approved corpora, then compose a response explicitly grounded in those artifacts.
The future RAG copilot is not "an LLM with a vector database." It is an evidence compiler with a language interface.
What a "RAG copilot" actually is (and what it isn't)
A production-grade RAG copilot has two planes:
- Data plane: ingestion, chunking, embeddings, indexing, retrieval, citation, provenance tracking
- Control plane: identity, entitlement enforcement, policy gating, audit logging, evaluation, supervisory workflows
It is not a system that:
- dumps top‑K chunks into a prompt and hopes for the best,
- treats citations as decoration,
- ignores access control in retrieval,
- lacks measurement beyond "users like it."
An audit-grade copilot behaves like a cautious reviewer: it cites, it abstains, it flags uncertainty, it respects boundaries, and it leaves a paper trail.
Visual 1 — Reference architecture for an audit-grade RAG copilot
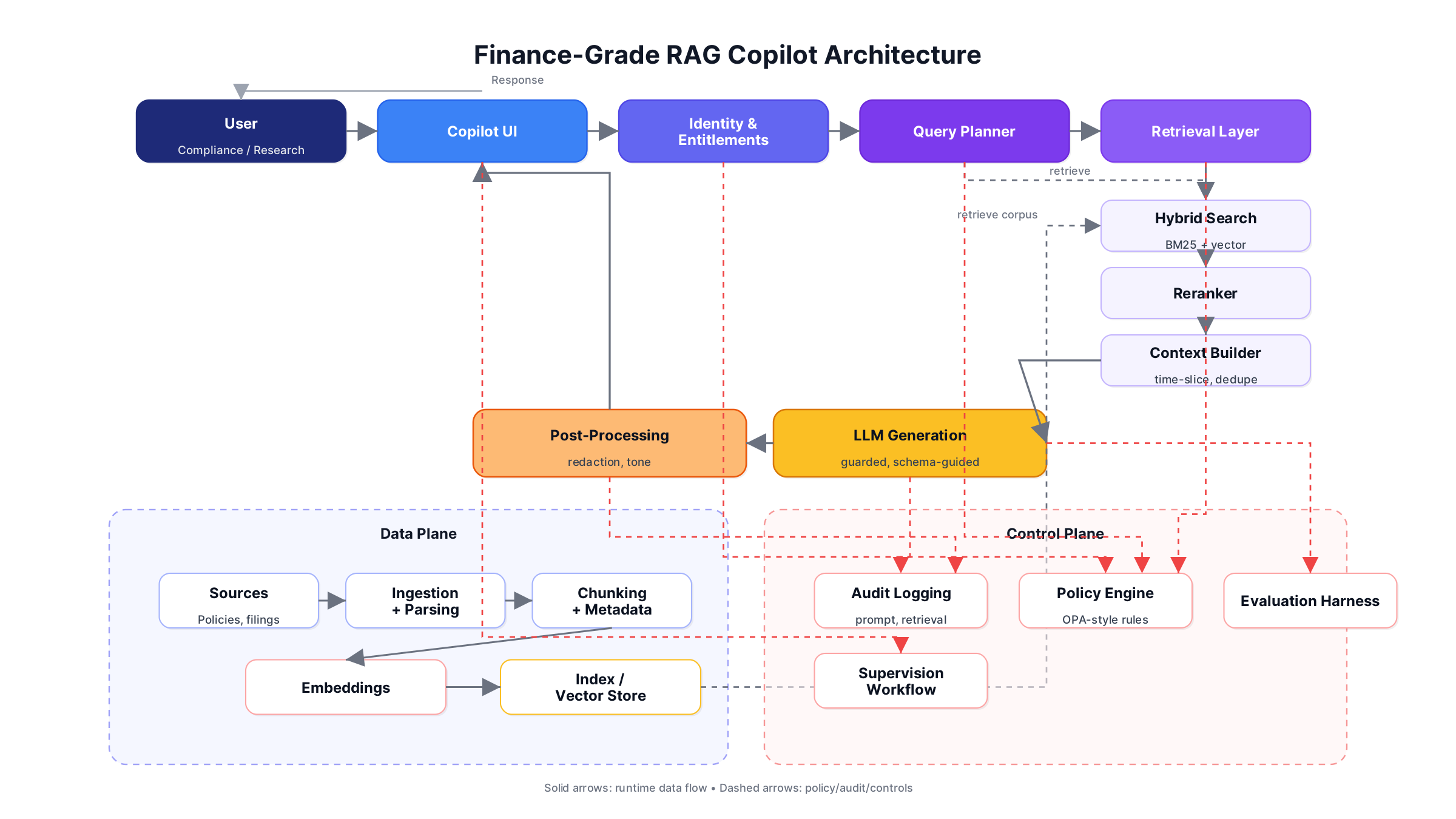
Key idea: In regulated environments, retrieval is a governed act. The system must prove it retrieved only what the user was allowed to access, and that the response was grounded in those artifacts.
How RAG copilots transform compliance workflows
Compliance work is largely the business of mapping language to obligations:
- "What does this policy require?"
- "Does this text violate the rule?"
- "Which controls apply to this scenario?"
- "What changed since last quarter?"
RAG copilots accelerate this by turning corpora into an interactive evidence layer—without breaking defensibility.
High-leverage compliance use cases
1) Change management
- Retrieve deltas across regulatory updates, internal memos, implementation plans
- Generate impact analysis with evidence links
- Track "as‑of" dates to avoid mixing old and new interpretations
2) Policy and procedure Q&A
- Answer "what do we do?" questions with policy citations
- Highlight ambiguous language and route to legal/compliance reviewers
- Provide "approved snippets" for frontline teams (support, sales enablement, operations)
3) Communications and claims review
- Ground review decisions in internal guidelines + external requirements
- Flag risky language patterns, missing disclosures, or prohibited claims
- Produce a reviewer memo with citations to policy text
4) Case triage and investigation support
- Summarize cases from tickets, communications, and structured context
- Keep a strict boundary: summarize only what's retrieved and permissible
- Produce structured outputs for downstream systems (case management, GRC)
Visual 2 — "Evidence-first" review interaction pattern (sequence)

The future here is "review memos on demand," where every conclusion is linked to evidence and the system knows when it must abstain or escalate.
How RAG copilots transform research workflows
Research in regulated organizations isn't just summarization. It's triangulation across heterogeneous sources:
- internal policies + historical decisions
- technical documentation + incident reports
- contracts, clauses, and legal language
- product requirements + SOPs
- vendor documentation + stakeholder notes
The limiting factor is rarely intelligence; it's time-to-context.
A RAG copilot helps by:
- finding the right fragments across massive corpora,
- presenting the evidence set compactly,
- generating structured notes that are reusable.
High-leverage research use cases
1) "What changed?" briefs across versions
2) Clause / requirement extraction with source pinpointing
3) Internal knowledge reuse without institutional amnesia
4) Due diligence on vendors, processes, and operational readiness (with provenance)
Best practices that separate demos from production
1) Treat retrieval as a first-class system, not a utility
Best practice:
- Hybrid retrieval (lexical + semantic) to reduce brittle misses
- Reranking to improve top‑K quality
- Domain-specific chunking strategies (policies ≠ contracts ≠ tickets ≠ tables)
- Metadata is non‑negotiable: author, timestamp, jurisdiction, doc type, confidentiality tier
Anti-pattern: "We embedded PDFs and hope the top chunk is relevant."
2) Enforce entitlements at retrieval time (not just at UI time)
In regulated environments, the greatest RAG risk isn't hallucination—it's unauthorized retrieval.
Best practice:
- Apply ABAC/RBAC filters as part of the retrieval query
- Segment indexes by business unit / region / confidentiality tier where needed
- Use policy-aware query planning that knows which corpora are allowed
Anti-pattern: Retrieve broadly and redact later.
3) Design answer formats for auditability
A defensible copilot should produce outputs that can be reviewed, stored, and explained.
Best practice: schema-guided generation with citations per claim.
Visual 3 — Example evidence-native answer schema
{
"question": "Is this marketing claim acceptable as written?",
"answer": "Likely needs revision. It implies performance certainty without required qualifiers.",
"decision": "REVISE",
"rationale": [
{
"claim": "Language implies certainty.",
"evidence": [
{
"doc_id": "POL-COMMS-014",
"snippet": "Avoid absolute claims or statements implying certainty unless explicitly approved...",
"location": "Section 3.2",
"as_of": "2025-08-01"
}
]
}
],
"required_changes": [
"Remove absolute language",
"Add required qualification statement"
],
"confidence": "medium",
"escalation": {
"needed": true,
"reason": "Jurisdiction nuance; request reviewer sign-off"
},
"audit": {
"retrieval_trace_id": "rt_abc123",
"policy_profile": "Comms-US"
}
}4) Build prompt-injection and data-exfiltration defenses into RAG
RAG systems are vulnerable to:
- malicious instructions hidden inside retrieved documents,
- cross-document contamination,
- tool misuse if the copilot can take actions.
Best practice:
- Treat retrieved text as untrusted input
- Neutralize instruction-like patterns
- Use least-privilege tool access + explicit approvals
- Maintain a system policy contract the model cannot override
5) Measurement: evaluate groundedness, not vibes
You need evaluation like risk management:
Retrieval metrics:
- precision@K / recall@K on curated queries
- coverage for required documents
- latency and stability
Answer metrics:
- attribution accuracy (does the citation truly support the claim?)
- groundedness (does it introduce unsupported facts?)
- abstention quality
- consistency under paraphrase
Operational metrics:
- escalation rate
- reviewer override rate
- time-to-resolution for reviews / cases
Anti-pattern: measuring only thumbs-up/down.
A controls matrix for audit-grade RAG copilots
| Risk | Control | What you should be able to prove |
|---|---|---|
| Unauthorized data access | ABAC/RBAC enforced in retrieval, index segmentation | Retrieval logs show user claims + allowed corpora + filtered results |
| Unsupported claims | Evidence-required schema + abstain policy | Each claim maps to citations; missing evidence triggers refusal/escalation |
| Outdated guidance | Time-sliced retrieval + document versioning | Answers reference "as-of" dates and current versions |
| Prompt injection via documents | Treat retrieval as untrusted; sanitize/parse; instruction filters | Stored evidence set + sanitization steps + policy decisions |
| PII leakage | PII detection + redaction + constrained outputs | Redaction logs and policy configuration |
| Poor audit readiness | Immutable logging + review workflows | End-to-end trace: prompt → retrieval → evidence → response → reviewer decision |
| Quality regression | Continuous evaluation harness + release gates | Evaluation reports by release; rollback triggers |
Where RAG copilots are heading next
- The copilot becomes a context compiler (structured evidence packs, not top‑K chunks)
- Retrieval becomes federated and time-aware ("answer as-of March 2024")
- "LLM + structured data" becomes standard (schemas, validators, rule overlays)
- Governance and evaluation become continuous (like CI/CD for reasoning)
Want an audit-grade copilot, not a demo?
Ishtar AI builds evidence-first RAG copilots and agent systems that are permission-aware, measurable, and production-ready. If you want a deployable system in weeks—not months—let's talk.